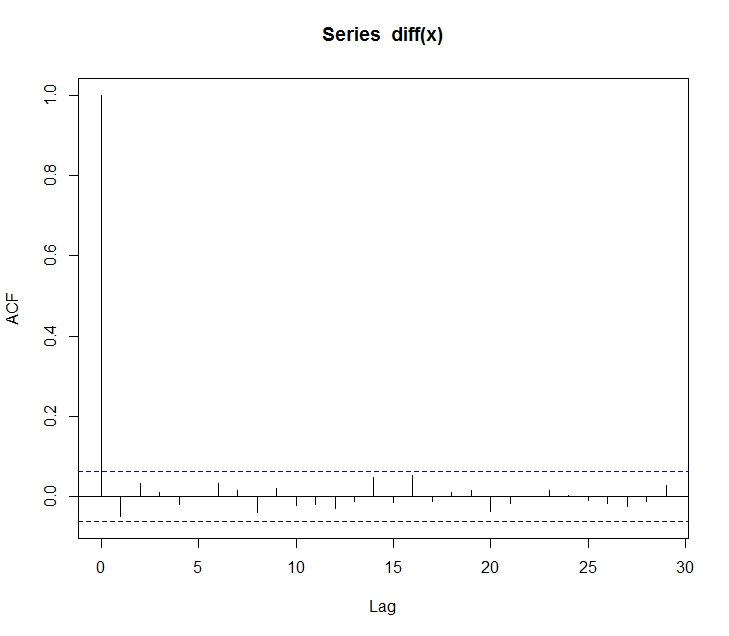
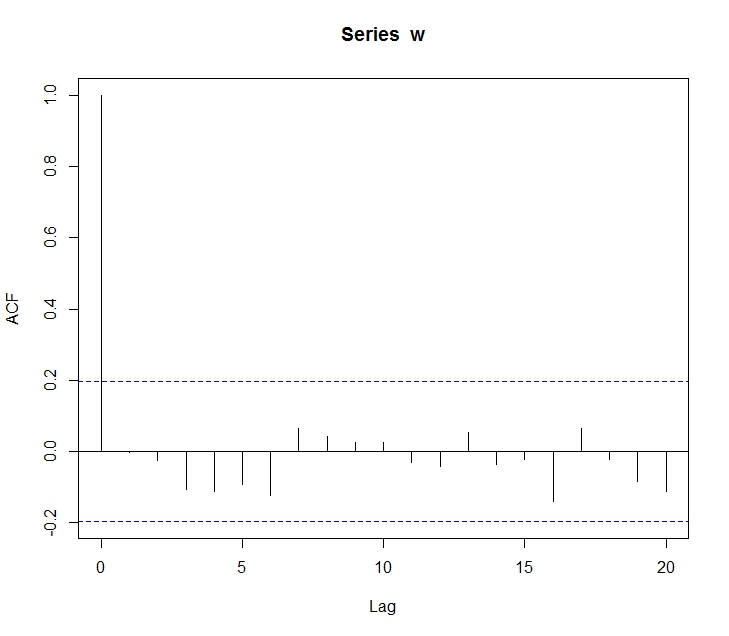
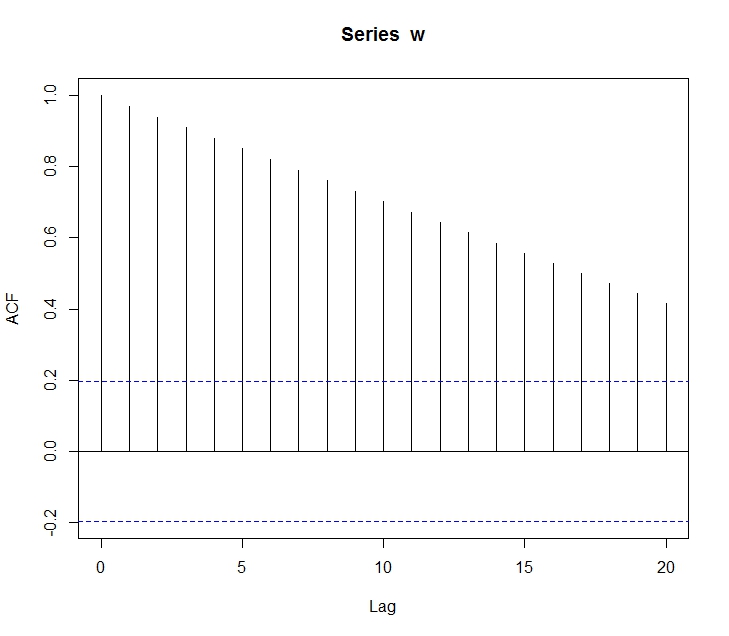
0. 앞으로
Michael L. Halls-Moore의 'Advanced Algorithmic Trading'을 스터디하며 요약 정리를 해 볼 심산이다. 처음으로 Bayesian Statistics와 그 예로 항상 등장하는 Coin toss 문제를 책에 제시한 내용을 가지고 요약해보겠다.
1. Bayesian vs. Frequentist
통계 문제에 확률을 적용하는 방법은 크게 'Bayesian'과 'Frequentist'가 있다. 'Frequentist'는 확률이란 어느 사건이 아주 많은 수의 수행 속에 나타난 빈도라고 생각하는 것이다. 그래서 이 경우 ideal 확률을 알아야 하며, 이 값이 변하지 않는다.
'Bayesian'의 경우, 이미 일어난 사건(data)와 앞으로 일어날 사건을 바탕으로 우리가 믿고있는 확률을 변화시킬 수 있다고 한다.
최근 이슈가되는 Machine Learning이나, 예전부터 많이 사용되는 Time Series Analysis는 모두 Bayesian Statistics에 바탕을두고있다.
2. Bayes' Rule
Bayes' Rule은 조건부 확률(conditional probability), 즉, 'B라는 일이 일어났을 때 A라는 일이 일어날 확률은 얼마인가?'에 대한 답을 찾기 위함이다. 이는 다음의 식으로 나타낼 수 있다.
$$
P(A|B) = \frac{P(A\cap B)}{P(B)} \\
P(B)P(A|B) = P(A\cap B)
$$
그리고 'A가 일어났을 때 B가 일어날 확률' 또한 다음과 같이 표현할 수 있다.
$$
P(B|A) = \frac{P(B\cap A)}{P(A)} \\
P(A)P(B|A) = P(B\cap A)
$$
여기서 $P(A\cap B) = P(B \cap A)$이므로 이를 풀어 쓰면 다음과 같다.
$$
P(A|B) = \frac{P(B|A)P(A)}{P(B)}
$$
$P(B)$는 다음과 같이 표현할 수 있다.
$$
P(B) = \sum_{a \in A} P(B \cap A) = \sum_{a \in A} P(B|A)P(A)
$$
즉, 교집합에 대한 확률을 모든 A의 이벤트에 대해 더해준 값이다. 그러므로 마지막으로 조건부 확률을 다음과 같이 쓸 수 있다.
$$
P(A|B) = \frac{P(B|A)P(A)}{ \sum_{a \in A} P(B|A)P(A)}
$$
3. Coin flipping에 Bayes 추론 적용하기
우리가 동전 던지기에서 알고싶은 것은 '동전이 얼마나 공정(fair)한가?'이다. 즉, 동전의 앞면이 나올 확률이 정말 거의 0.5에 가까운가를 알고싶은 것이다. Bayes 추론을 이 문제에 적용하기위해 다음과 같은 과정을 따라야 한다.
1) Assumptions - 동전은 무조건 두 결과(앞, 뒤) 중 하나만 나온다고 가정한다. 물론 동선을 던졌을 때 서 있을 수 있지만, 이런 상황은 제외한다. 그리고 각 시도에서 나오는 결과는 다른 시도에서 나오는 결과와 독립적이며, 이 공정성(fairness)는 어느 시도에서건 안정적(stationary)이므로 시간에 따라 달라지거나 하지 않는다. 여기서 공정성은 $\theta$라는 인수로 표현하자.
2) Prior Beliefs - 추론을 적용하기 위해 이 prior beliefs(선행 믿음?)을 정량화해야 한다. 이는 우리가 찾아볼 공정성의 분포를 특정하는 것으로 귀결된다.
3) Experimental Data - 이제 동전을 던져 실제 데이터를 뽑아낸다. 이 때 어떤 $\theta$가 주어졌을 때 해당 실제 결과가 나올 확률이 필요한데, 이 것이 likelihood function이다.
4) Posterior Beliefs - 이제 앞의 Bayes' rule을 이용하여 데이터에 기반한 새로운 확률을 구한다. 앞서 prior beliefs 과정에서 Beta distribution와 Bernoulli likelihood function을 사용하면 posterior에서도 beta distribution을 얻을 수 있는데, 이렇게 posterior와 prior가 같은 형태의 분포로 표현되는 것을 conjugate priors라고 한다.
5) Inference - 구해진 posterior belief를 기반으로 동전의 공정성을 추정한다.
앞서의 Bayes' Rule로 표현한 다음 식과 위의 과정을 대입해보면 다음과 같다.
$$
P(\theta | D) = P(D|\theta)P(\theta) / P(D)
$$
여기서 D는 data이다.
- $P(\theta)$ - prior. 여기서 data D에 대한 감안은 없다.
- $P(\theta | D)$ - posterior. 수정된 우리의 믿음이라고 보면 된다.
- $P(D| \theta)$ - likelihood. 어떤 인수 $\theta$가 있을 때 관찰한 데이터가 나올 확률이다.
- $P(D)$ - evidence. 모든 $\theta$에 대해 D가 나올 확률을 더한 확률
3.1 Bernoulli Distribution의 Likelihood Function
확률 변수 $k$가 동전 던지기의 결과를 나타낸다고 하면 $k \in \{ 0, 1 \}$이다. 여기서 앞면이 나올 확률(공정성)을 $\theta$라 했으니, $\theta$가 주어졌을 때 $k$의 확률을 다음과 같이 쓸 수 있다.
$$
P(k|\theta) = \theta^{k}(1-\theta)^{1-k}
$$
위의 식을 다시 해석하면 특정 $\theta$가 주어졌을 때 $k$의 확률을 나타내므로 결국 likelihood function으로 해석할 수 있다.
이제 동전을 여러번 던진다고 하자. 각각의 던지는 행동은 독립적이므로 각각의 확률을 곱하면 총 확률을 구할 수 있다. 즉, 다음과 같은 식으로 쓸 수 있다.
$$
P(\{k_1, \ldots , K_N\}|\theta) = \prod_{i} P(k_i | \theta) = \prod_{i} \theta^{k_i}(1-\theta)^{1-k_i}
$$
N번 던졌을 때 z번의 앞면이 나왔다면 위의 식은 다음과 같이 쓸 수 있다.
$$
P(z, N|\theta)=\theta^{z} (1-\theta)^{N-z}
$$
3.2 Prior Beliefs의 정량화
앞서 얘기했듯이 $\theta$에 대한 분포를 일단 정해야 한다. 여기서 $\theta \in [0, 1]$이니 beta distribution을 사용한다. beta distribution의 PDF(확률밀도함수)는 다음과 같다.
$$
P(\theta | \alpha, \beta) = \theta^{\alpha - 1} ( 1- \theta)^{\beta - 1} / B(\alpha, \beta)
$$
여기서 $B(\alpha, \beta)$는 값을 0과 1사이에 위치시키기 위한 표준화 상수(normalization constant)로서 다음과 같이 쓴다.
$$
B(\alpha, \beta) = \frac{\Gamma (\alpha)\Gamma (\beta)}{\Gamma (\alpha + \beta)} = \frac{(\alpha - 1)!(\beta - 1)!}{(\alpha + \beta - 1)!}
$$
위 분포의 $\alpha$와 $\beta$에 따른 모습은 다음 그림과 같다.
Beta prior(beta distribution으로 표현한 prior)의 $\alpha , \beta$를 이용하여 조금 더 친숙한 mean, variance를 표현할 수 있다. 이는 다음과 같다.
$$
\mu = \frac{\alpha}{\alpha + \beta}, \\
\sigma = \sqrt{\frac{\alpha \beta}{(\alpha + \beta)^2(\alpha + \beta + 1)}}
$$
3.3 Posterior 계산하기
Bayes' rule을 이용하여 posterior를 바꿔보자. 일단 위의 likelihood 함수 등을 이용하면 다음과 같이 표현할 수 있다.
$$
\begin{eqnarray}
P(\theta | z, N) &=& P(z, N|\theta)P(\theta) / P(z, N) \\
&=& \theta^{z} (1-\theta)^{N-z} \theta^{\alpha - 1}(1-\theta)^{\beta - 1} / [B(\alpha, \beta)P(z, N)] \\
&=& \theta^{z+\alpha - 1}(1-\theta)^{N-z+\beta - 1} / B(z+\alpha, N-z+\beta)
\end{eqnarray}
$$
실제 coding을 해서 그 distribution을 그려보면 다음과 같이 횟수가 늘어날 수록 $\theta$가 0.5 근처로 몰리는 것을 볼 수 있다.